科研论文中p值和显著性水平的关系 P值及其计算方法(4)
科研论文中p值和显著性水平的关系

公式中:
· SE 是两组样本之间差别的标准误差
· σ1 是第一组的标准差
· n1 是第一组的样本数量
· σ2 是第二组的标准差
· n2 是第二组的样本数量
步骤7:求t分数
t分数是用于度量估计值(或称为一组待验数据)与已知参考值(或称为另一组参考数据)之间的平均偏离程度相对于其 标准误差 的比例,这个程度可以告诉我们两组数据是否显著不同。计算t分数的公式是

其中:
· t0是计算得到的分数
· 上划线x1-x2两组数据平均值之差
· SE是两组数据的标准误差
步骤8:确定自由度
自由度(dF)即每组变量可以有多少个值可以选择用于分析。若两组样本进行比较,那么应该用两组样本数相加并减去二(实际上应该严格描述为各组样本数减一再相加)。
例如:如果有两组数据一组有10个样本,另一组有20个样本,那么第一组的自由度是9,第二组的自由度是19,两组一共有28个自由度。
步骤9:使用T表查找P值
因为小样本量的随机测试均值的分布不是正态分布,而是T分布。因为T分布的计算函数比较复杂,所以一般通过查t值表来获得P值。
下面是一个t值表:
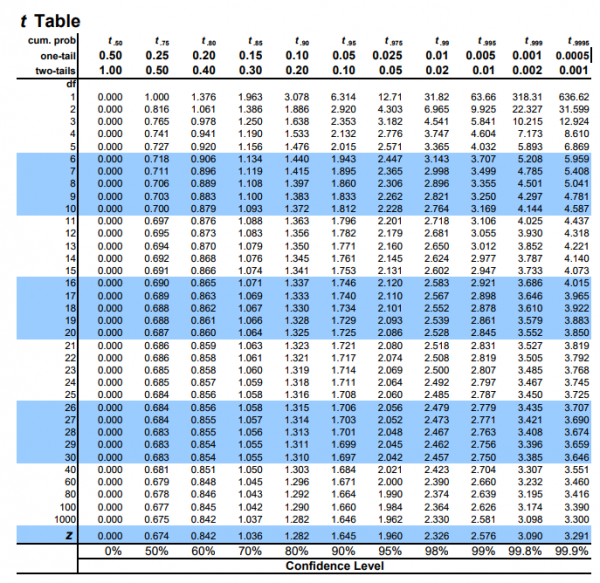
假设我们的实验采用单侧测试,两组数据总共有28个自由度,计算出来的t值是3.5左右。
1. 我们首先在最左侧df(自由度)一列查找,找到自由度为28那一行;
2. 然后再此行搜索我们的t值,我们可以发现大概是在左侧两列的数值(3.408-3.674)之间;
3. 在这两列顶部one-tail(单侧)一行查看对应的p值为0.001到0.0005之间。
根据这个p值我们即可判断,我们测试的两组数据的 差异极其显著 。
总结
通过本文了解了P值和统计学显著性的涵义之后,读者可以在今后阅读科研论文时 尝试理解 其中涉及统计学显著性的数据的内容。
而对于某些有数据分析能力但对统计学假设测试分析尚不太熟悉的读者(包括某些统计应用程序的开发者),希望这部分读者通过本文了解了P值的算法之后,可以大概理解求取P值的统计学思路;
以便在自己的工作中逐步尝试理解更多的统计学细节(当然具体计算还是推荐采用计算工具哈)。
本文分享的P值及其计算方法跟科研论文中p值和显著性水平的关系的全面知识讲解,希望能帮到您。